Tracking Bugs¶
So far, we have assumed that failures would be discovered and fixed by a single programmer during development. But what if the user who discovers a bug is different from the developer who eventually fixes it? In this case, users have to report bugs, and one needs to ensure that reported bugs are systematically tracked. This is the job of dedicated bug tracking systems, which we will discuss (and demo) in this chapter.
from bookutils import YouTubeVideo
YouTubeVideo("bJzHYzvxHm8")
Prerequisites
- You should have read the Introduction to Debugging.
import bookutils.setup
import Intro_Debugging
Synopsis¶
To use the code provided in this chapter, write
>>> from debuggingbook.Tracking import <identifier>
and then make use of the following features.
This chapter provides no functionality that could be used by third-party code.
Reporting Issues¶
So far, we have always assumed an environment in which software failures would be discovered by the very developers responsible for the code – that is, failures discovered (and fixed) during development. However, failures can also be discovered by third parties, such as
- Testers whose job it is to test the code of developers
- Other developers using the code
- Users running the code as it is in production
In all these cases, developers need to be informed about the fact that the program failed; if they won't know that a bug exists, it will be hard to fix it. This means that we have to set up mechanisms for reporting bugs – manual ones and/or automated ones.
What Goes in a Bug Report?¶
Let us start with the information a developer requires to fix a bug. In a 2008 study [Bettenburg et al, 2008], Bettenburg et al. asked 872 developers from the Apache, Eclipse, and Mozilla projects to complete a survey on the most important information they need. From top to bottom, these were as follows:
Steps to Reproduce (83%)¶
This is a list of steps by which the failure would be reproduced. For instance:
- I started the program using
$ python Debugger.py my_code.py.- Then, at the
(debugger)prompt, I enteredrunand pressed the ENTER key.
The easier it will be for the developer to reproduce the bug, the higher the chances it will be effectively fixed. Reducing the steps to those relevant to reproduce the bug can be helpful. But at the same time, the main problem experienced by developers as it comes to bug reports is incomplete information, and this especially applies to the steps to reproduce.
Stack Traces (57%)¶
These give hints on which parts of the code were active at the moment the failure occurred.
I got this stack trace:
Traceback (most recent call last): File "Debugger.py", line 2, in <module> handle_command("run") File "Debugger.py", line 3, in handle_command scope = s.index(" in ") ValueError: substring not found (expected)
Even though stack traces are useful, they are seldom reported by regular users, as they are difficult to obtain (or to find if included in log files). Automated crash reports (see below), however, frequently include them.
Test Cases (51%)¶
Test cases that reproduce the bug are also seen as important:
I can reproduce the bug using the following code: ```python import Debugger
Debugger.handle_command("run") ```
Non-developers hardly ever report test cases.
Observed Behavior (33%)¶
What the bug reporter observed as a failure.
The program crashed with a
ValueError.
In many cases, this mimics the stack trace or the steps to reproduce the bug.
Screenshots (26%)¶
Screenshots can further illustrate the failure.
Here is a screenshot of the
Debuggerfailing in Jupyter.
Screenshots are helpful for certain bugs, such as GUI errors.
Expected Behavior (22%)¶
What the bug reporter expected instead.
I expected the program not to crash.
Configuration Information (< 12%)¶
Perhaps surprisingly, the information that was seen as least relevant for developers was:
- Version (12%)
- Build information (8%)
- Product (5%)
- Operating system (4%)
- Component (3%)
- Hardware (0%)
The relative low importance of these fields may be surprising as entering them is usually mandated in bug report forms. However, in [Bettenburg et al, 2008], developers stated that
[Operating System] fields are rarely needed as most [of] our bugs are usually found on all platforms.
This not meant to be read as these fields being totally irrelevant, as, of course, there can be bugs that occur only on specific platforms. Also, if a bug is reported for an older version, but is known to be fixed in a more current version, a simple resolution would be to ask the user to upgrade to the fixed version.
Reporting Crashes Automatically¶
If a program crashes, it can be a good idea to have it automatically report the failure to developers. A common practice is to have a crashing program show a bug report dialog allowing the user to report the crash to the vendor. The user is typically asked to provide additional details on how the failure came to be, and the crash report would be sent directly to the vendor's database:
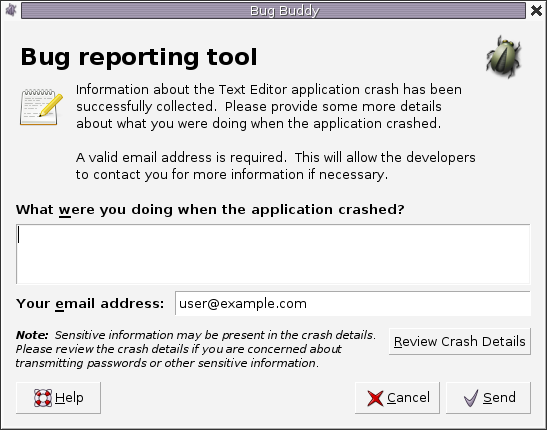
The automatic report typically includes a stack trace and configuration information. These two do not reveal too many sensitive details about the user, yet already can help a lot in fixing a bug. In the interest of transparency, the user should be able to inspect all information sent to the vendor.
Besides stack traces and configuration information, such crash reporters could, of course, collect much more - say the data the program operated on, logs, recorded steps to reproduce, or automatically recorded screenshots. However, all of these will likely include sensitive information; and despite their potential usefulness, it is typically better to not collect them in the first place.
Effective Issue Reporting¶
When writing an issue report, it is important to look at it from the developer's perspective. Developers not only require information on how to reproduce the bug; they also want to work effectively and efficiently. The following aspects will all help developers with that:
- Have a concise summary. A good summary should quickly and uniquely identify a bug. Make it easy to understand such that the reader can know if the bug has been reported and/or fixed.
- Be clear and concise. Provide necessary information (as shown above) and avoid any extras. Use meaningful sentences and simple words. Structure the report into enumerations and bullet lists.
- Do not assume context. Make no assumption that the developer knows all about your bug. Find out whether similar issues have been reported before and reference them.
- Avoid commanding tones. Developers enjoy autonomy in their work, and coming across as too authoritative hurts morale.
- Avoid sarcasm. Same as above. If you think you can get a volunteer to fix a bug in an open source program for you with sarcasm or commands – good luck with that.
- Do not assume mistakes. Do not assume some developer (or anyone) has made a mistake. In many cases, issues can be resolved on your side.
- One issue per report. If you have multiple issues, split them in multiple reports; this makes it easier to process them.
An Issue Tracker¶
At the developer's end, all issues reported need to be tracked – that is, they have to be registered, they have to be checked, and of course, they have to be addressed. This process takes place via dedicated database systems, so-called bug tracking systems.
The purposes of an issue tracking system include
- to collect and store all issue reports;
- to check the status of issues at all times; and
- to organize the debugging and development process.
Let us illustrate how these steps work, using the popular Redmine issue tracking system.
Setting up Redmine
To install Redmine, we followed the instructions at https://gist.github.com/johnjohndoe/2763243. These final steps initialize the database:
import subprocess
def with_ruby(cmd: str, inp: str = '', timeout: int = 30, show_stdout: bool = False) -> None:
print(f"$ {cmd}")
shell = subprocess.Popen(['/bin/sh', '-c',
f'''rvm_redmine=$HOME/.rvm/gems/ruby-2.7.2@redmine; \
rvm_global=$HOME/.rvm/gems/ruby-2.7.2@global; \
export GEM_PATH=$rvm_redmine:$rvm_global; \
export PATH=$rvm_redmine/bin:$rvm_global/bin:$HOME/.rvm/rubies/ruby-2.7.2/bin:$HOME/.rvm/bin:$PATH; \
cd $HOME/lib/redmine && {cmd}'''],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True)
try:
stdout_data, stderr_data = shell.communicate(inp, timeout=timeout)
except subprocess.TimeoutExpired:
shell.kill()
# stdout_data, stderr_data = shell.communicate(inp)
# if show_stdout:
# print(stdout_data, end="")
# print(stderr_data, file=sys.stderr, end="")
raise
print(stderr_data, file=sys.stderr, end="")
if show_stdout:
print(stdout_data, end="")
def with_mysql(cmd: str, timeout: int = 2, show_stdout: bool = False) -> None:
print(f"sql>{cmd}")
sql = subprocess.Popen(["mysql", "-u", "root",
"--default-character-set=utf8mb4"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True)
try:
stdout_data, stderr_data = sql.communicate(cmd + ';',
timeout=timeout)
except subprocess.TimeoutExpired:
sql.kill()
# stdout_data, stderr_data = sql.communicate(inp)
# if show_stdout:
# print(stdout_data, end="")
# print(stderr_data, file=sys.stderr, end="")
raise
print(stderr_data, file=sys.stderr, end="")
if show_stdout:
print(stdout_data, end="")
with_ruby("bundle config set without development test")
with_ruby("bundle install")
with_ruby("pkill sql; sleep 5")
try:
with_ruby("mysql.server start", show_stdout=True)
except subprocess.TimeoutExpired:
pass # Can actually start without producing output
with_mysql("drop database redmine")
with_mysql("drop user 'redmine'@'localhost'")
with_mysql("create database redmine character set utf8")
with_mysql("create user 'redmine'@'localhost' identified by 'my_password'")
with_mysql("grant all privileges on redmine.* to 'redmine'@'localhost'")
with_ruby("bundle exec rake generate_secret_token")
with_ruby("RAILS_ENV=production bundle exec rake db:migrate")
with_ruby("RAILS_ENV=production bundle exec rake redmine:load_default_data", '\n')
Starting Redmine
from multiprocess import Process
def run_redmine(port: int) -> None:
with_ruby(f'exec rails s -e production -p {port} > redmine.log 2>&1',
timeout=3600)
def start_redmine(port: int = 3000) -> Tuple[Process, str]:
process = Process(target=run_redmine, args=(port,))
process.start()
time.sleep(5)
url = f"http://localhost:{port}"
return process, url
redmine_process, redmine_url = start_redmine()
Remote Control with Selenium
To produce this book, we use Selenium to interact with user interfaces and obtain screenshots.
Selenium is a framework for testing Web applications by automating interaction in the browser. Selenium provides an API that allows one to launch a Web browser, query the state of the user interface, and interact with individual user interface elements. The Selenium API is available in a number of languages; we use the Selenium API for Python.
A Selenium web driver is the interface between a program and a browser controlled by the program.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
The following code starts a Firefox browser in the background, which we then control through the web driver.
BROWSER = 'firefox'
with_ruby("pkill Firefox.app firefox-bin")
Note: If you don't have Firefox installed, you can also set BROWSER to 'chrome' to use Google Chrome instead.
# BROWSER = 'chrome'
When running this outside of Jupyter notebooks, the browser is headless, meaning that it does not show on the screen.
from bookutils import rich_output
# HEADLESS = not rich_output()
HEADLESS = True
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.common.by import By
def start_webdriver(browser: str = BROWSER, headless: bool = HEADLESS,
zoom: float = 4.0) -> WebDriver:
if browser == 'firefox':
options = webdriver.FirefoxOptions()
if browser == 'chrome':
options = webdriver.ChromeOptions()
if headless and browser == 'chrome':
options.add_argument('headless')
else:
options.headless = headless
# Start the browser, and obtain a _web driver_ object such that we can interact with it.
if browser == 'firefox':
# For firefox, set a higher resolution for our screenshots
options.set_preference('layout.css.devPixelsPerPx', repr(zoom))
redmine_gui = webdriver.Firefox(options=options)
# We set the window size such that it fits
redmine_gui.set_window_size(500, 600) # was 1024, 600
elif browser == 'chrome':
redmine_gui = webdriver.Chrome(options=options)
redmine_gui.set_window_size(1024, 510 if headless else 640)
return redmine_gui
redmine_gui = start_webdriver(browser=BROWSER, headless=HEADLESS)
We can now interact with the browser programmatically. First, we have it navigate to the URL of our Web server:
redmine_gui.get(redmine_url)
To see what the "headless" browser displays, we can obtain a screenshot. We see that it actually displays the home page.
from IPython.display import display, Image
Image(redmine_gui.get_screenshot_as_png())

Screenshots with Drop Shadows
By default, our screenshots are flat. We add a drop shadow to make them look nicer. With help from https://graphicdesign.stackexchange.com/questions/117272/how-to-add-drop-shadow-to-a-picture-via-cli
import tempfile
def drop_shadow(contents: bytes) -> bytes:
with tempfile.NamedTemporaryFile() as tmp:
tmp.write(contents)
convert = subprocess.Popen(
['convert', tmp.name,
'(', '+clone', '-background', 'black', '-shadow', '50x10+15+15', ')',
'+swap', '-background', 'none', '-layers', 'merge', '+repage', '-'],
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout_data, stderr_data = convert.communicate()
if stderr_data:
print(stderr_data.decode("utf-8"), file=sys.stderr, end="")
return stdout_data
def screenshot(driver: WebDriver, width: int = 500) -> Any:
return Image(drop_shadow(redmine_gui.get_screenshot_as_png()), width=width)
screenshot(redmine_gui)

First Registration at Redmine
redmine_gui.get(redmine_url + '/login')
screenshot(redmine_gui)

redmine_gui.find_element(By.ID, "username").send_keys("admin")
redmine_gui.find_element(By.ID, "password").send_keys("admin")
redmine_gui.find_element(By.NAME, "login").click()
time.sleep(2)
if redmine_gui.current_url.endswith('my/password'):
redmine_gui.get(redmine_url + '/my/password')
redmine_gui.find_element(By.ID, "password").send_keys("admin")
redmine_gui.find_element(By.ID, "new_password").send_keys("admin001")
redmine_gui.find_element(By.ID, "new_password_confirmation").send_keys("admin001")
display(screenshot(redmine_gui))
redmine_gui.find_element(By.NAME, "commit").click()

redmine_gui.get(redmine_url + '/logout')
redmine_gui.find_element(By.NAME, "commit").click()
This is what the Redmine tracker starts with:

After we login, we see our account:

Creating a Project
Let us check out the projects by clicking on "Projects".

We can now enter a project name and a description.


We start with a list of projects.

Let us choose the (one) "debuggingbook" project.

Reporting an Issue¶
The most basic task of a bug tracker is to report bugs. However, a bug tracker is a bit more general than just bugs – it can also track feature requests, support requests, and more. These are all summarized under the term "issue".
Let us take the role of a bug reporter – pardon, an issue reporter – and report an issue. We can do this right from the Redmine menu.

Let's give our bug a name:
issue_title = "Does not render correctly on Nokia Communicator"
issue_description = \
"""The Debugging Book does not render correctly on the Nokia Communicator 9000.
Steps to reproduce:
1. On the Nokia, go to "https://debuggingbook.org/"
2. From the menu on top, select the chapter "Tracking Origins".
3. Scroll down to a place where a graph is supposed to be shown.
4. Instead of the graph, only a blank space is displayed.
How to fix:
* The graphs seem to come as SVG elements, but the Nokia Communicator does not support SVG rendering. Render them as JPEGs instead.
"""



Clicking on "Create" creates the new issue report.

Our bug has been assigned an issue number (#1 in that case). This issue number (also known as bug number, or problem report number) will be used to identify the specific issue from this point on in all communication between developers. Developers will know which issues they are working on; and in any change to the software, they will refer to the issue the change relates to.
Over time, issue databases can grow massively, especially for popular products with several users. As an example, consider the Mozilla Bugzilla issue tracker, collecting issue reports for the Firefox browser and other Mozilla products.
Yes, it is that many! Look at the bug IDs in this recent screenshot from the Mozilla Bugzilla database:

Let us enter a few more reports into our issue tracker.
Adding Some More Issue Reports
def new_issue(issue_title: str, issue_description: str) -> Any:
redmine_gui.get(redmine_url + '/issues/new')
redmine_gui.find_element(By.ID, 'issue_subject').send_keys(issue_title)
redmine_gui.find_element(By.ID, 'issue_description').send_keys(issue_description)
redmine_gui.find_element(By.NAME, 'commit').click()
return screenshot(redmine_gui)
new_issue("Missing a Chapter on Parallel Debugging",
"""I am missing a chapter on (automatic) debugging of parallel and distributed systems,
including how to detect and repair data races, log message passing, and more.
In my experience, almost all programs are parallel today, so you are missing
an important subject.
""")

new_issue("Missing a PDF version",
"""Your 'book' does not provide a printed version. I think that printed books
* offer a more enjoyable experience for the reader
* allow me to annotate pages with my own remarks
* allow me to set dog-ear bookmatks
* allow me to show off what I'm currently reading (do you have a cover, too?)
Please provide a printed version - or, at least, produce a PDF version
of the debugging book, and make it available for download, such that I can print it myself.
""")

new_issue("No PDF version",
"""Can I have a printed version of your book? Please!""")

new_issue("Does not work with Python 2.7 or earlier",
"""I was deeply disappointed that your hew book requires Python 3.9 or later.
There are still several Python 2.x users out here (I, for one, cannot stand having to
type parentheses for every `print` statement), and I would love to run your code on
my Python 2.7 programs.
Would it be possible to backport the book's code such that it would run on Python 3.x
as well as Python 2.x? I would suggest that you add simple checks around your code
such as the following:
```
import sys
if sys.version_info.major >= 3:
print("The result is", x)
else:
print "The result is", x
```
As an alternative, rewrite the book in Python 2 and have it automatically translate to
Python 3. This way, you could address all Python lovers, not just Python 3 ones.
""")

new_issue("Support for C++",
"""I had lots of fun with your 'debugging book'. Yet, I was somewhat disappointed
to see that all code examples are in and for Python programs only. Is there a chance
to get them to work on a real programming language such as C or C++? This would also
open the way to discuss several new debugging techniques for bugs that occur in these
languages only. A chapter on C++ move semantics, and how to fix them, for instance,
would be highly appreciated.
""")

Managing Issues¶
Let us now switch sides and take the view of a developer whose job it is to actually handle all these issues. When our developers log in, the first thing they see is that there are a number of new issues that are all "open" – that is, in need to be addressed. (For a typical developer, this may well be the first task of the day.)

Clicking on "View all issues" shows us all issues reported so far.

Let us do some bug triaging here. Bug report #2 is not a bug – it is a feature request. We invoke its "actions" pop-up menu and mark it as "Feature".

The same applies to bugs #3 and #4 (missing PDF) and #6 (no support for C++). We mark them as such as well.

The fact that we marked these issues as "feature requests" does not mean that they will not be worked on – on the contrary, a feature requested by management can have an even higher priority than a bug. Right now, though, we will give our first priority to the bugs listed.
Assigning Priorities¶
After we have decided the priority for individual bugs, we can make this decision explicit by assigning a priority to each bug. This allows our co-developers to see which things are the most pressing to work on.
Let us assume we have an important customer for whom fixing issue #1 is important. Through the context menu, we can assign issue #1 a priority of "Urgent".

We see that issue #1 is now listed as urgent.

On top of priority, some issue trackers also allow assigning a severity to an issue, describing the impact of the bug:
- Blocker (also known as Showstopper): Blocks development and/or testing, for instance by breaking build processes.
- Critical: Application crash. Loss of data.
- Major: Loss of function.
- Minor: Incomplete function.
- Trivial: Minor issues in user interfaces and documentation.
- Enhancement: Request of a new feature or an improvement in an existing one.
The severity would be an important factor in determining the priority of an issue.
Assigning Issues¶
So far, all the listed bugs are "unassigned", which means that there is no developer who is currently working on them. Let us assign the "urgent" issue #1 to ourselves, such that we have something to do.

By choosing the Actions menu, clicking on Assignee, and then << me >>, we can assign the issue to ourselves.

Of course, we could also go and assign the issue to other developers – depending on their competence and current workload. Very clearly, the ability to assign issues to individuals is a feature for managers.
Resolving Issues¶
Let us switch perspectives again, and now take a developer's role – that is, we now work on the issues assigned to us. We get these by clicking on "Issues assigned to me":

By clicking on the issue number, we can see all details about the issue.

We can inspect all features of the issue, including its history.

Let us assume that we do have everything in hand we need to fix the bug. (Including a Nokia Communicator device for testing, that is.) This will take some time, during which we won't need our bug database.

Let us now assume that we actually have fixed the bug. This means that we have to go back to our bug database such that we can mark the bug as resolved. For this, we open the issue again and click on "Edit", and then change the status from "New" to "Resolved".

At the bottom, we can add more notes.

After clicking on "Submit", we are done. Time for the next bug to fix!

The Life Cycle of an Issue¶
We have successfully reported an issue (as some third party), assigned it (as a manager), and resolved it (as a developer). Great! However, the steps we have been going through are just one way an issue might be handled.
Resolutions¶
First, an issue can have multiple resolutions besides being fixed. Typical resolutions include the following:
FIXED¶
A fix for this issue is made and committed. This is the resolution we have seen for the "Nokia Communicator" bug #1, above.
INVALID¶
The problem described is not an issue. This is what happens to entries in the issue database that actually do not describe an issue, or that do not provide sufficient information to address it.
WONTFIX¶
The issue described is indeed an issue, but will never be fixed. This is a decision of which features (and fixes!) are part of the product, and which ones are not. Our listing of hypothetical issues, above, has an entry complaining that the book "does not work with Python 2.7 or earlier". This will not be fixed.
DUPLICATE¶
The issue is a duplicate of an existing issue. In our listing of hypothetic issues, we have two issues reporting problems with PDF exports. By making one of these a duplicate of the other. we can ensure that both will be fixed (and checked) at the same time.
If your product has several users, your issue database will have several duplicates, as multiple users will stumble across the same bugs. Some developers consider such duplicates as a burden, as identifying duplicates takes time. However, the study by Bettenburg et al.~[Bettenburg et al, 2008] points out that such duplicates have their value, too. One developer is quoted as
Duplicates are not really problems. They often add useful information. That this information were filed under a new report is not ideal thought.
WORKSFORME¶
The developer could not reproduce the issue, and the code provided no hints on why such a behavior might occur. Such issues are often reopened when more information becomes available.
An Issue Life Cycle¶
With this in mind, we can sketch the individual states an issue report goes through: After submission (NEW), the report is assigned to a developer (ASSIGNED), and then resolved (RESOLVED) with one of the resolutions listed above.
Unfortunately, software development is more complicated than that. There are many things that can happen while an issue is being worked on.
- When an issue report comes in, it may be resolved as "invalid" or "duplicate" before even being assigned to a developer.
- The developer assigned to an issue might change.
- Fixes suggested by developers might be subject to quality assurance, to ensure that they
- fix the error under all circumstances
- do not introduce new errors
- Issues may be reopened if the fix is inadequate or new information becomes available.
With this in mind, the states an issue report can go through become a bit more complex. Note how issues start in a state of "UNCONFIRMED" as long as nobody has assessed them, and how issues are marked as "CLOSED" (the final state) only after the resolution has been checked by quality assurance.
Such states (and the implied transitions between them) can be found in any issue tracking system. The actual names may vary (ASSIGNED is also known as IN_PROGRESS; instead of or besides CLOSED, one can also have VERIFIED), but their meanings are always the same.
Whatever the states and resolutions are called (and they can be configured, anyway), the important thing is that they be used consistently for your project and in your organization. This is how at any point, any team member can see
- what the most pressing tasks are;
- what he or she should be working on; and
- what the overall state of the project is.
The latter point is particularly important, since an issue tracker need not only be used for tracking bugs, but also for tracking and assigning features – notably features that have been decided to be part of the product. Hence, if you want to have some new feature implemented, you can mark it as a "NEW" issue, break it into subfeatures, also all marked as "NEW", and then assign the associated subtasks to individual developers. The feature would then be ready when all subtasks are completed as "FIXED".
This way, you can organize an entire software project through the issue tracker. Start with the first issue "The product is missing", and then keep on defining and assigning subtasks; when all are resolved, the product will be ready. Since some issue trackers (including Redmine) also allow developers to report how far they got with resolving an issue (say, "10%", "50%", or "90%"), you can even estimate how long resolving the open issues will take.
Over time, an issue database not only becomes an important tool for managing bug fixing and organizing software development, it also holds a trove of data about where, what, and why specific issues were addressed. In the next chapter, we will explore how to mine and evaluate such data.
Lessons Learned¶
- In an organization, fixing bugs and issues is best organized through an issue tracker.
- An issue tracker allows issue reports
- to be collected;
- to assign them with a state (from NEW to CLOSED) in its life cycle;
- to be assigned to developers; and
- to assign them with a resolution (including FIXED, DUPLICATE, and WORKSFORME).
- Issue trackers can organize the entire software development, including new products and features.
Next Steps¶
- The chapter on mining version histories describes how to mine and analyze the data from bug and version databases.
Background¶
The survey by Bettenburg et al. [Bettenburg et al, 2008] is the seminal work on how developers make use of bug reports. The study by Bertram et al. [Bertram et al, 2010] highlights how issue trackers are not just databases, but "a focal point for communication and coordination for many stakeholders within and beyond the software team."
The report by [Glerum et al, 2009] provides details on how Windows Error Reporting automates the processing of error reports coming from an installed base of a billion machines, providing impressive numbers on bugs in the wild.
Research on bug databases has very much focused on how to make predictions such as automatically identifying duplicates [Wang et al, 2008], possible bug locations [D. Kim et al, 2013], or automatically assigning issues to developers [Anvik et al, 2006]. Herzig et al. [K. Herzig et al, 2013], however point out that much of the information in bug database is not classified properly enough, for instance to reliably distinguish between bugs and features.
Mozilla's Bugzilla bug database is one of the largest publicly available issue databases. It is worth browsing for real-world bug reports, and also contains important articles on how to write and use bug reports.
 The content of this project is licensed under the
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
The source code that is part of the content, as well as the source code used to format and display that content is licensed under the MIT License.
Last change: 2023-11-11 18:05:06+01:00 •
Cite •
Imprint
The content of this project is licensed under the
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
The source code that is part of the content, as well as the source code used to format and display that content is licensed under the MIT License.
Last change: 2023-11-11 18:05:06+01:00 •
Cite •
Imprint